Das Thema Proxmox Cluster ist ein ziemlich großes Thema und versuche hier die Grundlagen zu erklären. Dabei gehe ich nicht auf Themen ein wie Shared Storage oder CEPH. Ich bin selber noch dabei zu lernen und habe aktuell nur die Grundlagen verstanden.
Ein Proxmox Cluster besteht aus mindestens drei Proxmox Nodes. Man kann auch einen zwei Node Cluster erstellen, dann sollte man aber ein QDevice nutzen oder muss die Votes einen Servers erhöhen, dazu aber später mehr.
Vorteile eines Clusters:
- Ein Webinterface für alle Server
- Die Möglichkeit VMs auf einen anderen Server einfach zu migrieren (verschieben)
- Replikation von VMs
- High Availability (HA) mit Shared Storage oder mittels Replikation
Nachteile eines Clusters:
- Mindestens drei laufende Systeme
Alle Artikel dieser Serie:
- Teil 1: Proxmox installieren
- Teil 2: Eine Proxmox VM anlegen
- Teil 3: Migration einer virtuelle Machine von ESXi zu Proxmox
- Teil 4: Migration Windows VM von ESXi zu Proxmox
- Teil 5: Trim in Proxmox-VMs nutzen
- Teil 6: Proxmox Backup auf NFS-Laufwerk
- Teil 7: Proxmox Speicher erweitern
- Teil 8: Einen Proxmox Cluster erzeugen
- Teil 9: Einen Proxmox Metric Server anlegen
- Teil 10: Der Proxmox Backup Server
- Teil 11: Proxmox Notifications
- Proxmox Tipps Sammlung
Proxmox Cluster erzeugen
Solltet ihr das Proxmox Post Install Script genutzt aben und HA abgewählt haben, müsst ihr es nun wieder aktivieren. Der Datenaustausch zwischen den Cluster Nodes wird über Corosync gehändelt. Dieses muss nun wieder aktiviert werden. Solltet ihr HA nutzen wollen, müsst ihr noch zwei weitere Dienste wieder aktivieren.
Corosync:
systemctl enable -q --now corosync
HA:
systemctl enable -q --now pve-ha-lrm
systemctl enable -q --now pve-ha-crmEinen Cluster zu erzeuge ist erst mal ganz einfach. Ihr geht auf einen Node eures Systems und beginnt mit „Create Cluster“. Dort vergebt ihr einen Namen für den Cluster und könnt ebenfalls zusätzliche Failover Netzwerklinks erzeugen. Anschließend geht ihr auf „Join information“ und kopiert diese. Wechselt nun zu eurem zweiten Node und geht auf „Join Cluster“. Fügt die kopierten Informationen ein und tragt das Passwort eures ersten Nodes ein. Fügt den Node nun über Join hinzu. Da der zweite Node nun neue Zertifikate erhält, müsst ihr die Verbindung zu dem Node neu aufbauen.
So verfahrt ihr mit jedem weiteren Node. Ich baue erst mal nur einen zwei Node Cluster auf und bin damit erst mal fertig. Im Webinterface seht ihr nun beide Nodes und könnt sie administrieren. Damit wäre der Cluster erst mal fertig, fast jedenfalls.
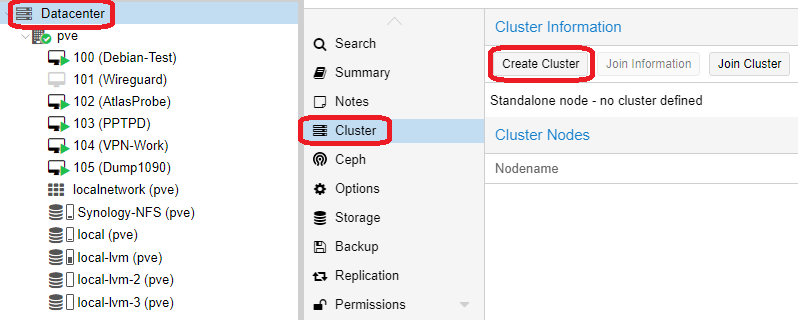

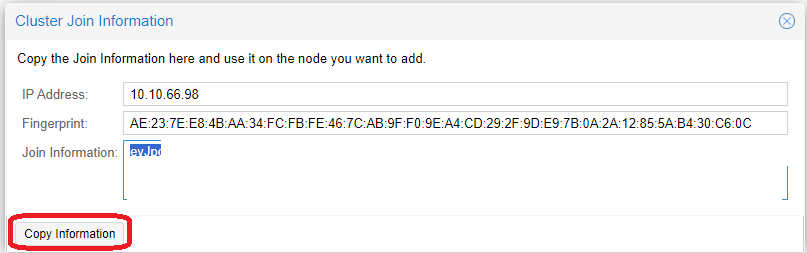
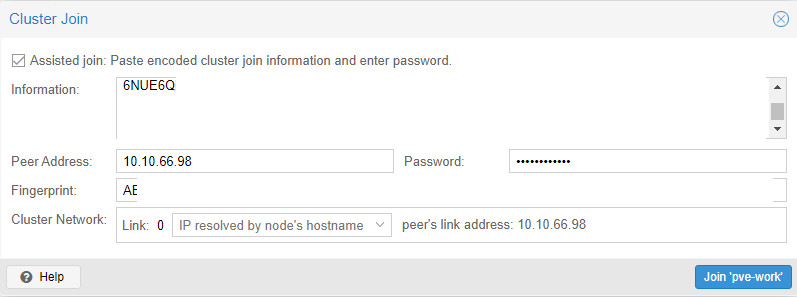

Ein Node kann nur einem Cluster hinzugefügt werden, solange er keine VMs hostet. Ihr bekommt eine Fehlermeldung und müsst eigentlich die VMs löschen. Der Grund ist, das VM IDs nur einmal vorhanden sein dürfen. Es gibt aber einen Trick den ihr nutzen könnt, aber nur wenn die VM IDs unterschiedlich sind:
- Stoppt die VMs des neuen Nodes
- Verschiebt die VM Konfigs mittels
mv /etc/pve/nodes/[node-name]/qemu-server/* /home/qemu-bck/ - Cluster Join durchführen
- Konfigs zurück kopieren
mv /home/qemu-bck/* /etc/pve/nodes/[node-name]/qemu-server/
Nun solltet ihr wieder eure VMs auf dem neuen Cluster-Node sehen.
Das Quorum
Solange beide Proxmox Nodes laufen, ist alles ok. Jedoch benötigt ein Cluster eine Mehrheit (Quorum) um entscheiden zu können. Jeder Node im Cluster hat eine Stimme (Vote) und es werden mindestens zwei Stimmen benötigt um damit Nodes funktionieren. Aktuell sehen sich beide Nodes und somit kommen wir auf zwei Stimmen und der Cluster läuft. Solltet ihr jedoch einen Nodes ausschalten, sehen sich beide nicht mehr und somit kommt nur noch eine Stimme zusammen. Damit wechselt der Cluster zu Read-only. VMs lassen sich nicht mehr stoppen oder starten und ihr könnt keine Einstellungen verändern. Aber warum?
In einem normalen HomeLab ohne HA ist das Thema erst mal nicht wichtig. Sobald man jedoch HA nutzt, ist es wichtig zu wissen wo das Problem liegt. In einem zwei Node Cluster kann der Node nicht wissen ob er selbst das Problem ist, oder der andere Node. Der Zustand nenne sich „Split Brain“. Wird HA verwendet, wäre es jetzt schlecht wenn das zweite System ebenfalls die VM startet. Denn wenn das Problem im Netzwerk lag und der Fehler behoben wurde, hat man nun zwei Instanzen mit der gleichen IP im Netz. Daher wird eine weitere Stimme benötigt. Wenn einer der Nodes dieses dritte System erreicht, ist das Quorum erfüllt und er kann seine Arbeit weiter führen.
Es gibt insgesamt zwei Ansätze um dieses Problem zu lösen. Der erste Ansatz ist die Verwendung eines QDevice, welches eine weitere Stimme darstellt. Dieses kann ein Raspberry Pi, eine VM oder ein Container sein, beides sollte jedoch nicht auf einem der Nodes laufen. Der zweite Ansatz wäre das erhöhen der Votes einens Nodes, damit er das Quorum alleine erfüllen kann. Letzteres ist in einem HomeLab ok, sobald aber HA nutzen wollten, geht es damit nicht, dann benötigt ihr zwingen einen dritten Node oder ein QDevice.
Das Quorum ist auch abhängig von der Anzahl der Nodes, da es immer eine Mehrheit geben muss:
| Nodes/Votes | Quorum |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
| 5 | 3 |
| 6 | 4 |
QDevice
Ein QDevice kann z.B. eine Raspberry Pi sein oder z.B. eine Debian System. Dort installiert ihr den QNet Daemon:
apt install corosync-qnetd
Anschließend installiert ihr auf beiden Cluster Nodes das Corosync QDevice. Öffnet dazu die Shell und gebt folgenden Befehl ein.
apt install corosync-qdevice
Auf einem der Cluder Nodes führt ihr folgenden Befehl aus. Damit sagt ihr dem Cluster wo er das QDevice erreicht. Dazu muss das QDevice mittels SSH als root erreichbar sein. Per Default kann root, auf einem Debain, nicht direkt per SSH anmelden. Dazu müsst ihr in der /etc/ssh/sshd_config den Eintrag PermitRootLogin yes setzen und danach den SSH Dienst neu starten.
pvecm qdevice setup QDevice-IP
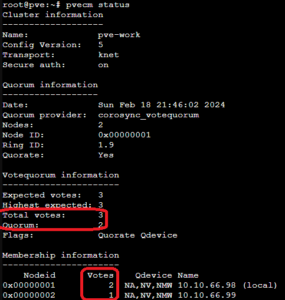
Mittels pvecm status könnt ihr den aktuellen Status des Cluster und des Quorum abfragen. Hier sieht man das es drei Votes gibt und das Quorum von 2 somit erfüllt ist.
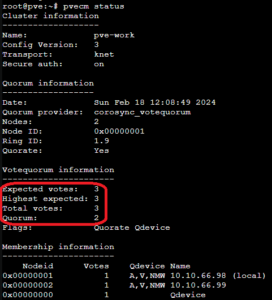
Solltet ihr später mal einen dritten realen Node dazu bauen, solltet ihr das QDevice mittels pvecm qdevice remove entfernen.
Proxmox Cluster Votes erhöhen
Wenn ihr z.B. einen zwei Node Cluster habt und ihr wollt nur ein System gelegentlich einschalten, dann könnt ihr auch die corosync.conf anpassen und einem Node zwei Votes, anstelle von einem, zuteilen. Somit würde dieses seine volle Funktion behalten, wenn der zweite Node abgeschaltet wird. Die corosync.conf findet ihr unter /etc/pve/corosync.conf . Zuerst erstellen wir ein Backup mittels cp /etc/pve/corosync.conf /etc/pve/corosync.conf.bak Anschließend könnt ihr die Datei editieren und die quorum_votes eines Nodes auf 2 erhöhen. Die config-version muss bei jeder Änderung um Eins erhöht werden. Die Einstellungen werden sofort übernommen.
nodelist {
node {
name: pve
nodeid: 1
quorum_votes: 1
ring0_addr: 10.10.66.98
}
node {
name: pve2
nodeid: 2
quorum_votes: 1
ring0_addr: 10.10.66.99
}
}
totem {
cluster_name: pve-work
config_version: 3
interface {
linknumber: 0
}
ip_version: ipv4-6
link_mode: passive
secauth: on
version: 2
}Man kann nun sehen das ein Node 2 Votes hat und somit immer das Quorum von 2 erfüllt. Ihr könnt jetzt aber nicht die Votes des zweiten Nodes ebenfalls auf zwei setzen, da dann das Quorum bei drei wäre.Die Mehrheit von 4 wäre 3.
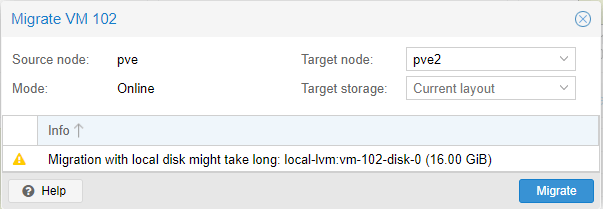
Migration
Migration ist eines der Features, welche ein Proxmox Cluster bietet. Ihr könnt damit eine VM einfach auf einen anderen Node verschieben um z.B. Wartungsarbeiten durchzuführen oder weil der aktuelle Node ausgelastet ist. Über den Button Migrate in der VM Ansicht könnt ihr die Migration starten. Bei einer Online Migration wird die VM ausfallfrei verschoben, ihr merkt quasi keine Unterbrechung. Laut Task Output gab es eine Unterbrechung von gerade mal 99 Millisekunden. Dieses Feature ist einfach genial und funktioniert perfekt.

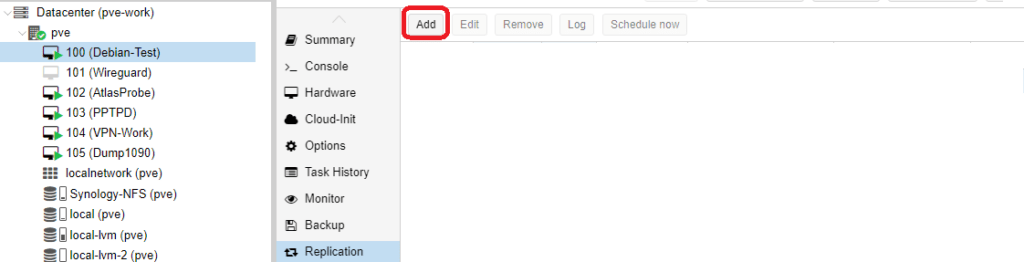
Replikation
Mittels Replikation könnt ihr regelmäßig die Daten einer VM auf einen anderen Node replizieren (Default alle 15 Minuten). Dieses ist quasi die Vorbereitung für HA, wenn man keinen Shared Storage nutzt. Replikation funktioniert nur mit ZFS Volumes, also nicht mit LVM. Ihr müsst also eventuell euren Storage umbauen, aber dank Backup und Restore ist das kein Problem. Nachteil ist, das ihr die Daten doppelt auf eurem Cluster liegen habt.
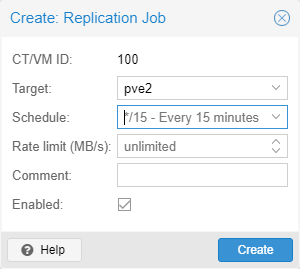
Um eine Replikation zu erzeugen, wechselt ihr zur betreffenden VM und wählt Replikation aus. Übner Add erzeugt ihr einen neuen Task und wählt dort das Ziel aus. Bei drei Nodes im Cluster, müsst ihr also zwei Tasks anlegen, für jedes Ziel einen eigenen. Unter Schedule könnt ihr das Intervall festlegen. Im Default sind 15 Minuten vorgegeben, somit habt ihr einen maximalen Datenverlust von 15 Minuten, sollten ein Node ausfallen und das spätere HA greifen.
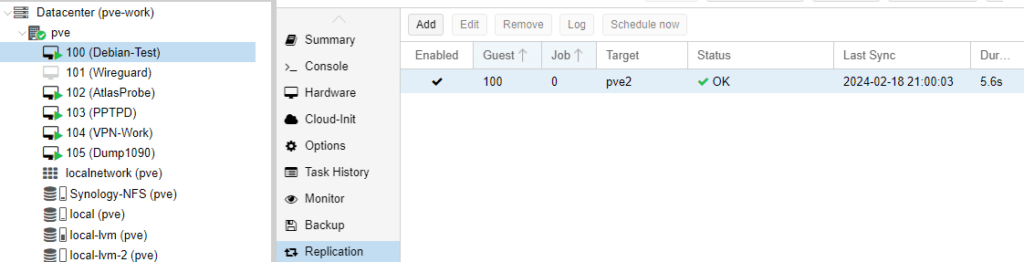
Proxmox Cluster HA
Wir haben uns darum gekümmert, das eine Kopie einer VM regelmäßig erzeugt wird, jedoch passiert noch nichts, falls ein Node ausfällt. Jetzt müssen wir noch HA für diese VM aktivieren. Wechselt dazu zur betreffenden VM und wählt Manage HA unter More. Passt eure Einstellungen an und fügt die HA über Add hinzu. Solltet ihr mehrere Nodes haben und nur bestimmt für HA nutzen, müsst ihr vorher Gruppen erzeugen, diese könnten dann hier auch ausgewählt werden. Im Datacenter unter HA seht ihr nun den aktuellen Status. In diesem Fall sit die VM gestartet auf dem Node pve. Sollte es nun zu einem Ausfall von pve kommen, dauert es ca. 1 Minute bis die VM auf pve2 gestartet wird. Wie ich finde, sehr einfach gemacht und leicht zu managen.
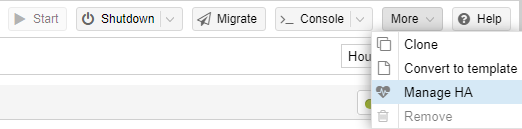
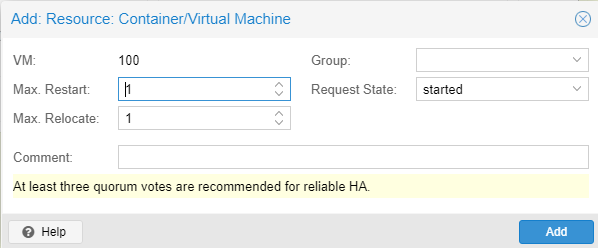
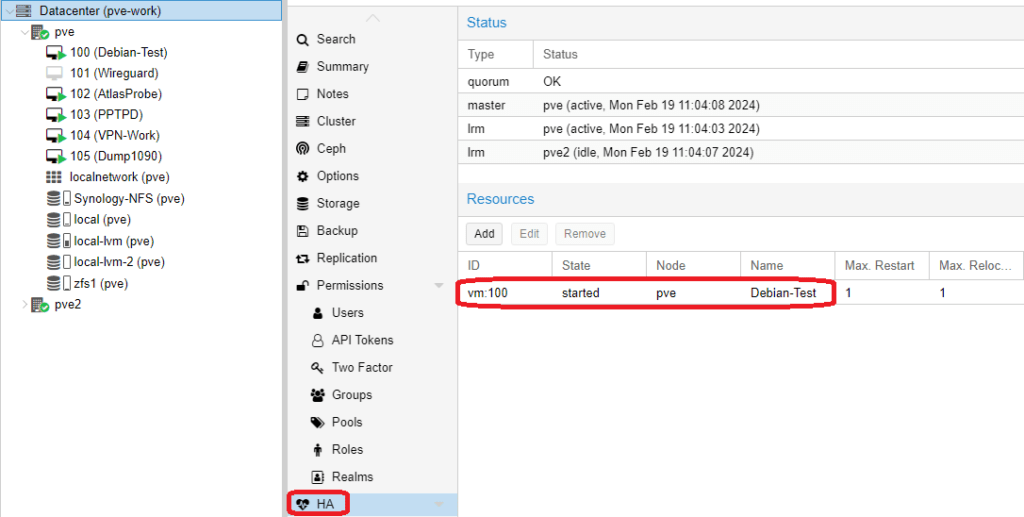
Wie ihr seht ist das Thema Cluster relativ einfach, sobald man das Thema Quorum und Votes verstanden hat. Ein Cluster bietet Features wie Migration und HA, welche für viele interessant sind.
Das Thema Shared Storage und Ceph werde ich wohl nicht mehr behandeln, aber warten wir es mal ab. Ihr müsst auch bedenken, das ich selber gerade ein Anfänger bin und noch viel für mich neu ist. Jedenfalls ist Proxmox für ein Homelab genau das Richtige und für mich jedenfalls der Ersatz für einen ESXi. Ich denke mal ich werde mir demnächst noch den Proxmox Backup Server anschauen und dann geht die Serie ihrem Ende entgegen.

Moin, danke für deinen Beitrag. Das hat mir geholfen es besser zu verstehen.
Ich würde gerne noch etwas über Ceph von dir lesen wollen. 🙂
Das kann ich verstehen, leider habe ich mich bisher damit selber 0 beschäftigt und es wird wohl so schnell auch nichts dazu kommen.
Danke für den hilfreichen Artikel!
Sehr cooler, verständlicher Artikel. Ich beschäftige mich mit dem Thema noch nicht sehr lange, finde das ganze Thema aber hier sehr gut abgehandelt.